三大组学哪个最难搞?
代谢组学
LC-MS
代谢组学是目前关注度颇高的组学方向,近几年代谢组学的项目数量几乎超过了蛋白质组。作为分析人员,当你真正着手代谢组学分析时,才能体会什么是无助三大组学,哪个分析难度最高、水最深?那当然是非代谢组学莫属。为什么?那么听小析姐一一道来。
首先,什么是代谢组学?
代谢组学(Metabonomics or Metabolomics) 是继基因组学和蛋白质组学之后发展起来的新兴的组学技术,是系统生物学的重要组成部分。用一张图就可以说清楚。
基因/转录组= 测核苷酸排列,4种核苷酸组成;蛋白组= 测氨基酸排列,20种氨基酸组成;代谢组 =测核苷酸+氨基酸+糖+有机酸+脂类等组成,每一类都有N种。
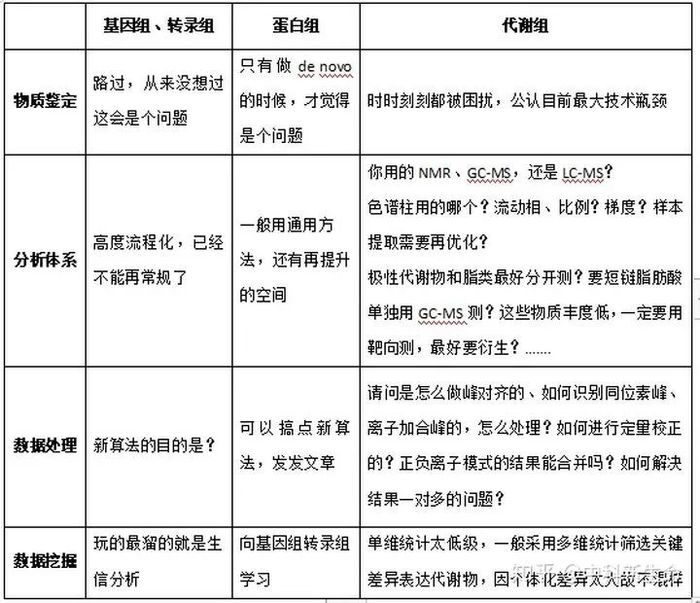
单维统计太低级,一般采用多维统计筛选关键差异表达代谢物,因为个体化差异太大所以不混样
分析化学没学好?色谱玩不溜?原始图谱不会看?算法不太懂?如果是这种情况,可能连代谢组学的门都难摸到。代谢组学做的好的平台,基本都是有N年分析化学经验的大牛。
对于生物领域研究的老师,也许我们并不需要过分关注检测分析实验的细节。但是,对于代谢组分析的一些基本知识,还是需要【知道】的。
因为,面对如此复杂的分析技术,我们需要一些必备基础认识,来帮助判断我们面前的代谢组数据,是否达到了基本的分析要求,是否有用于后续的生物研究的价值。以下简单讨论我们认为需要知道的几个重要基本问题。在此,我们主要讨论基于LC-MS平台的代谢组分析。
(1)LC-MS平台对代谢物的覆盖最广、灵敏度更高。从文献中已报道的同时使用多种分析平台的数据来看,都是LC-MS获得的数据量显著更多;
(2)相比于GC-MS,LC-MS一般无需衍生处理,分析平行性更好,更适合大规模样本的分析;
(3)使用LC-MS平台的人员和机构更多,包括很多做NMR和GC-MS的代谢组学专家都已转向LC-MS。
1、很多时候你可能把张三和李四搞错了
首先,我们先讨论上文提到的代谢组目前最主要的技术瓶颈——代谢物鉴定。因为,物质鉴定是所有结果的基础,即使某检测方法能检测到的数据量再多、定量能力再灵敏、定量结果再精确,如果这个信号是代谢物张三还是代谢物李四不能确定的话,所获得的数据有何意义,也根本无从谈起表达是否有差异、功能是否有变化等后续问题。为了探讨这个问题,我们从业内人士反复提到的名词——代谢物标准品库说起。
标准品库,是指将纯化的、结构已经确证的代谢物的标准品(通常是商业化的),在某一特定分析检测体系下进行检测,获得该代谢物的标准结果信息,包括保留时间、分子量、二级(或多级)质谱图谱等。
在其他组学的分析领域中,通常不会听到,但在代谢组学里,这是个代谢物鉴定的门槛,而且是十分关键的门槛。为什么代谢组鉴定,对标准品库有这么高的要求呢?
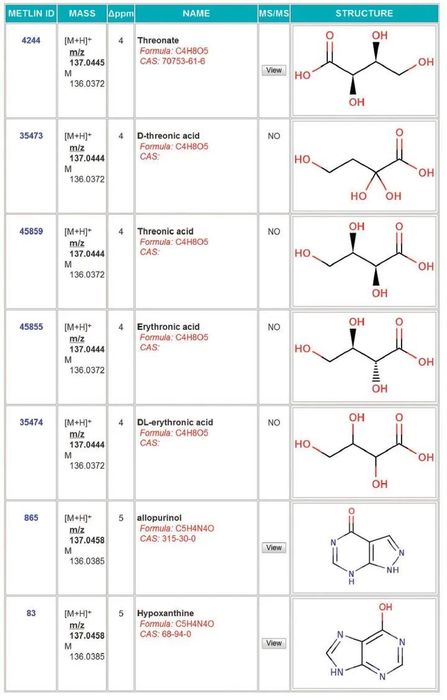
下面这两个物质,元素组成完全不同,但是分子量非常相近,从小数点后第三位才开始不一样:
而下面这两个物质,一个是明星代谢物——TCA cycle里的柠檬酸,一个是半乳糖的代谢产物。两者分子量、化学式完全一样,但结构不同,功能也完全不同:
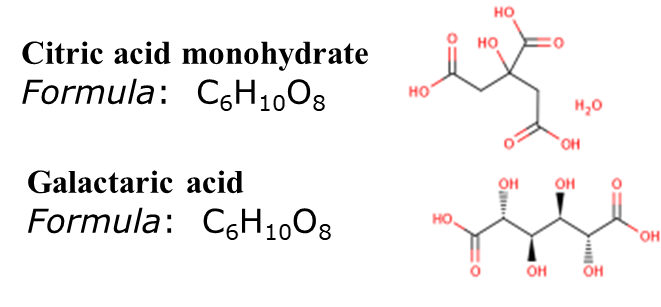
这就是代谢组分析里,令人闻风丧胆的同分异构体。而悲剧的是,这种同分异构体在代谢组结果中大量存在。雪上加霜的是,同一个代谢物还会以(M-H)-、 (M+H)+、(M+Na)+、(M+H-H2O)+等多种不同离子形式存在。问题来了,如何区分和鉴定如此复杂的代谢物呢?目前代谢物的鉴定有不同的层级:
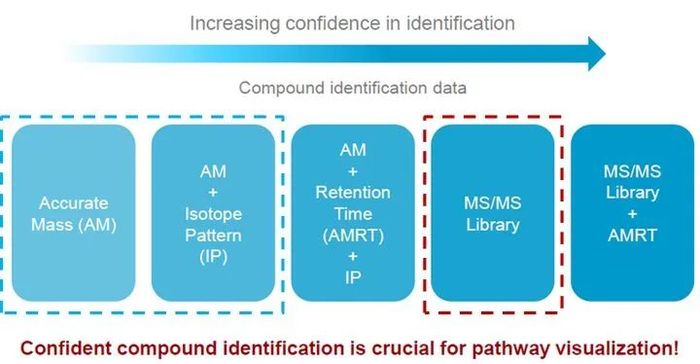
一般认为要鉴定到MS/MS这一级,即质谱的二级图谱水平才能有一定的准确性。这就要用到我们上面说到的标准品图谱库。然而,崩溃的是,对于LC-MS/MS分析,同一个代谢物在不同仪器平台上获得的二级图谱是不同的,仍然以柠檬酸为例:
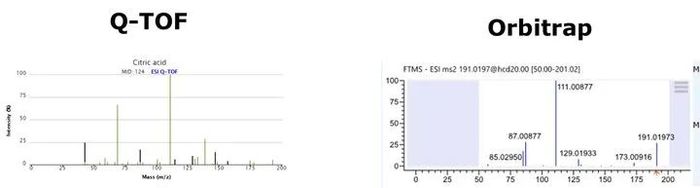
同一个仪器平台上,不同分析条件下获得的图谱也是不同的,以柠檬酸为例:
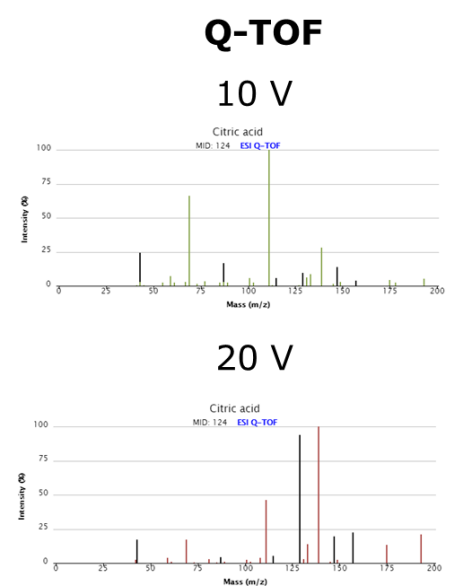
所以,标准品库是较难通用的,最好是在自己的平台上建,而且样本分析时也要采用建库相同的分析条件,这样获得的标准品图谱才能更准确地用于样本中代谢物的比对。所以,即使是标准品库,也分为自建标准品库和公共标准品库两种,两者的效果是有差异的,大家一定要注意。国内代谢组研究最权威的专家,对此的说法更具代表性:

在此,纠正一个误区:所谓建立标准品库,是否就是花钱买一堆标准品,然后上机检测,获得图谱就行了,人人都能做,没有技术含量,无所谓质量好坏的工作吗?
以我们目前已建立的几乎国内最全的代谢标准品图谱库的经验可以告诉大家:标准品库的建立绝非一件很不简单的工作:
(1)你以为同一个标准品打出图谱就只有一种吗?其实,不仅不同碎裂能级打出的图谱不同,在不同浓度、甚至不同时间下,同一个物质打出的图谱也会有所差别。所谓高质量的标准品库,会在不同碎裂能级、不同浓度、不同时间条件下采集图谱。因为,不同浓度下打出的图谱,可以更好地对应不同实际样本中代谢物实际浓度的丰度差异情况;不同时间打出的图谱,可以减少因为实际样本检测时质谱本身状态的改变所造成的差异。
(2)一个标准品库的背后,除了图谱、荷质比等实验信息,还有一个关键组成——匹配算法。一次非靶代谢组分析往往能够获得上千个feature,不可能人工拿着实验图谱与标准图谱一一比对,所以需要算法软件来匹配。最后的匹配效果,除了由标准品图谱和实验图谱质量的决定,匹配算法一样至关重要!!如何对图谱进行去噪、如何进行相似性打分,是正向匹配还是负向匹配,如何评价比对结果的可靠性等等,这里有一大堆的问题。至少对我小编这种不懂算法的人来说,一个优秀的匹配算法背后,简直是难以企及的另一个世界。
总之,即使都是标准品库,也会存在质量的高低。一个高质量的自建标准品库,不仅需要在不同条件下获得高质量的标准图谱,还需要准确的匹配算法进行图谱比对,两者都起着决定性作用。最后,所获得的的鉴定结果,仍需有经验的分析人员再进行人工核对,毕竟代谢组的数据复杂度较高,软件匹配出来的也不完全是一对一的结果或100%准确。
如开头所说,在实验条件方面,测序技术或普通蛋白质组技术的实验方法是大体统一的,因为其分析对象是同一类物质,其理化性质单一。而代谢组学分析对象的理化性质复杂多样,相应地实验条件的选择也差别很大,导致不同平台采用的代谢组实验条件大多不太一样,包括样本制备的方法、
的选择、色谱分离洗脱条件、质谱采集参数等。那么,如何理解实验条件对数据结果的影响呢?为了避免把这部分内容讲成分析化学学习资料,我们分享两个简单的实例,来体会不同实验条件的选择可能造就不同
所得分析效果的差异。
实例1:某次讲座结束,一位自己做代谢组实验的老师提问:我们的研究比较关注TCA循环和某些氨基酸类的代谢物,但是实验做了好几次,结果中上述物质非常少,请教原因是什么?当然还年轻的小编,遇到专业做代谢组的老师,还有点小紧张的,但是我第一反应就是问,老师您用的什么
?老师的回答跟我预期一致,果然就是反相C18
(早期大家做代谢组,用的最多的就是这个)。我们平台做非靶代谢组学,常规情况下推荐使用亲水柱。因为,通过比对测试,亲水柱获得的结果要显著多于反相C18。而反相C18柱,则更适用于脂质组的分析。此外,还需考虑柱子的稳定性、耐用性问题。总之,在代谢组学研究中,
的选择很有讲究。
实例2:是不是
选好了,大家的分析结果就差不多了?以下示例结果,来自于两个
,两者采用的
及质谱型号等是完全相同的:
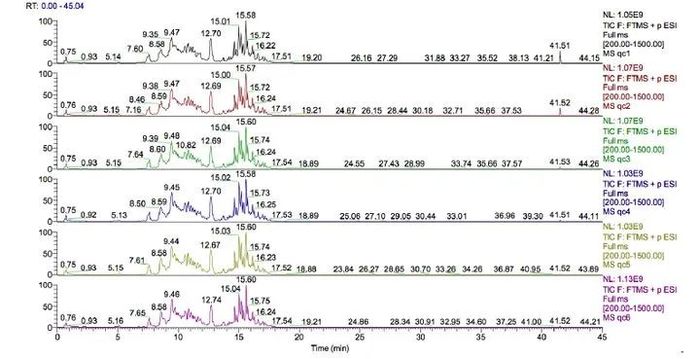
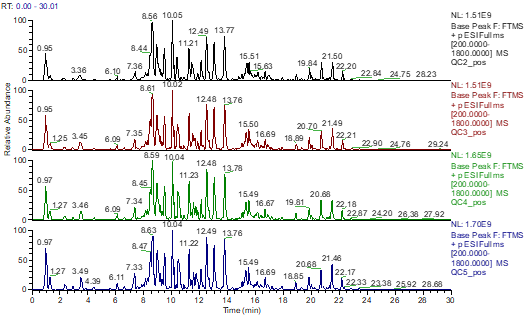
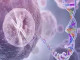
但是,大家会直观的发现:其效果有很大差异。第一张图中,大部分信号峰集中出现在某个时间段内,像连绵起伏的山峦,共洗脱严重且峰型不好;第二张图中,出峰时间均匀分布在整个洗脱时间内,峰型尖锐,峰型好、分离效果好。色谱峰型不理想、共洗脱严重,对后续质谱信号的采集效率、峰积分定量的准确性等都会产生影响,导致鉴定数量、定量能力和可靠性的问题。同一个
、同一个质谱,但两者的效果相差如此之大吗?对,因为除了
一样,其他色谱分离的条件都相差很大。第二张图的实验条件,是我们
人员专门摸索出来的。
代谢组的技术难度高、坑多,仅跟大家聊了鉴定和色谱问题,就花了很大篇幅,而且只能算是初略介绍。其他实验因素包括:样本提取的优化和评价、如何对原始数据进行更优的处理、如何考察积分定量的准确性、最后人工校验的注意等很多环节,均会显著影响代谢组最终的实验结果和效果,而且如上所述,很多环节都有技能能力、经验的积累在其中,目前为止都没有形成一个完全固定的统一分析模式。
建议大家要有一个意识:与基因组、转录组不同,代谢组学技术目前仍然有很多tricks,不同平台的分析效果可能会有较大差异;
代谢物的鉴定是目前代谢组的最大难题,标准品图谱库是关键门槛。标准品库也有in house自建库、共平台建库之分,也有不同的构建标准和匹配算法之分,对应的效果也有差异。
代谢组的实验方法和条件的选择性较多,且对结果影响很大。所以,文章发表通常都会对实验方法的描述有着相对更细节的要求。对于没有提供详细实验方法的数据,要谨慎对待。
中科新生命
展源
何发








加载更多